The ViWi Vision-Aided Millimeter Wave Beam Tracking Competition (ViWi-BT) at ICC 2020
Motivation
-
The large numbers of antennas deployed at millimeter wave (mmWave) base stations makes it challenging for these systems to support highly-mobile applications.
This is mainly due to the high training overhead associated with finding the best beamforming vectors which scales with the array size. As a way to combat this
overhead problem, recent work has turned to machine learning to uncover patterns in observed beam sequences and perform proactive beam prediction. While this approach can have good potential for simple line-of-sight scenarios,
it will likely struggle in real wireless environments with multiple users, multiple blockages, and rich dynamics. In response to that, the ViWi-BT competition aims at encouraging new
machine learning approaches to tackle this beam tracking problem via leveraging not only the observed beam sequences, but also the visual data (RGB images in particluar). The turn to
visual data as a supplemeentary source of information is motivated by two key factors: (i) the fact that images are rife with information about the environments they
are depicting, and (ii) the major strides computer vision has taken in image comprehension with the help of deep learning.
Competition Task
Level.1: predicting a single future beam (m=1)
Level.2: predicting three future beams (m=3)
Level.3: predicting five future beams (m=5)
The main task of ViWi-BT is to proactively predict future m mmWave beams of a user using n = 8 previously-observed and consecutive beams and RGB images. More specifically, a scenario with two small-cell mmWave base-stations is considered. The two base-stations are assumed to be installed on lamp posts, and they are assumed to be equiped with a mmWave uniform linear array antenna and three RGB cameras each. The two base-stations are serveing users moving along a street and its side walks. For one user, a length n = 8 sequence of beams and corresponding images is observed at one base-station and, then, used as an input to a prediction algorithm, which is expected to identify the future m beams of the same user with high fidelity. The base-station is assumed to employ a fixed beam steering codebook, so the beamforming veectors are completely defined by their beam indices.
Using m, the challenge defines a three-tier prediction task:
Development Dataset
-
No localization information is provided. The sequence of RGB images provided with any user's beam sequence is not accompanied with user localization information.
The beam tracking task does not include visual user tracking. Thus, the future RGB images are not provided as labels and should not be included in the prediction process. They, however, could be used for analysis and debugging.
The contestants will be provided with two different datasets, namely training, and validation. The training and validation datasets comprise a collection of equal-size sets. Each one has 13 pairs of consecutive images and beam indices. The first 8 represent the observed beams for a user and the sequence of image where the user appears, and the last 5 pairs are the label pairs, i.e., they have the future beams of the same user and the corresponding images. It is important to note two things here:
Finally, the datasets are provided in three optional formats: .mat, .csv, and .h5. More technical details on the data structure of both datasets could be found in the "README.txt" file enclosed with the developement package
Test Dataset
-
The test dataset will have a similar structure to that of the training and validation datasets; it will consist of a collection of equal-size sets, each of which has
8 pairs of consecutive images and beam indices. Since this dataset is meant for evaluation, these 8 pairs are all observed images and beams that are expected to be used
to predict the future beam indices. This dataset will be released closer to the time the contestants are expected to submit their evaluation results. See the time line below.
Participation and Challenge Development Package
Registartion:
To participate in the competition and receive the development package, please register to the competition using this link. You will receive an email with your team ID and links to the two datasets (3 formats per each). Using those datasets, each participating team should develop ONE solution to the task defined above.
Initial Evaluation:
To assess the quality of the proposed solutions, a test dataset will be released on April 8, 2020 (see the timeline below), and the participates will be asked to evaluate their proposals.The evaluation results should be organized into a csv file (format description could be found in the README.txt file enclosed with the deveelopment package) and uploaded through the submission page. See the file submission tab above. Each team will have 3 chances to submit their results and obtain instant scores. The top-10 teams will be invited to the live demo at the ICC Machine Learning in Communications Workshop (video conferencing may be considered as well).
Live Demo and Final Evaluation:
A second test dataset will be released on the workshop day, and the final solutions will be invited to participate in a live demonstration, which will determine the winners.
Scoring and Ranking Process
Scoring:
- ti(m) is the ith target beam sequence which includes the correct future m beams.
- pi(m) is the sequence of predicted future m beams.
- ||..||1 is the first norm.
- σ is a penalization factor that is set to 0.5.
- U is the total number of data samples in the validation or test sets.
Ranking:
To evaluate the quality of the predicted future sequence of every tier, the following average score function for each tier is employed:
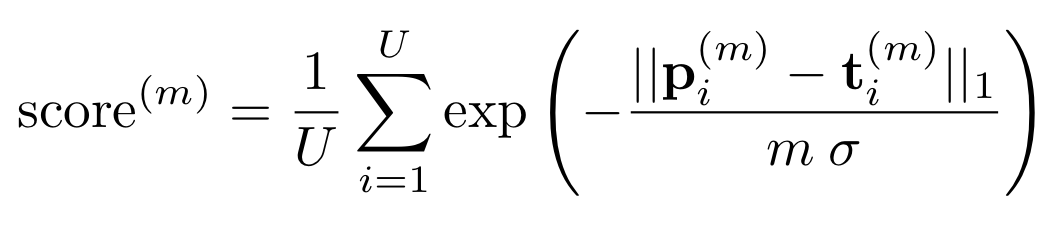
where:
An overall score that indicates the overall performance of a solution is defined as a weighted average of the three-tier scores. It is given by:
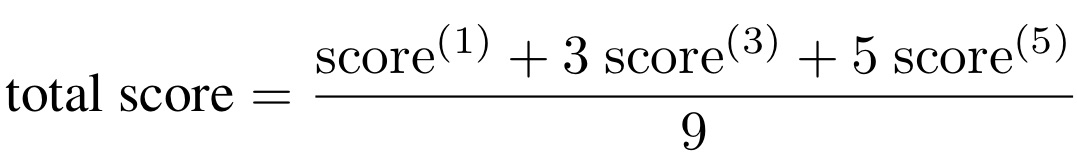
The proposals of different teams will be assessed using a two-round process. The first round requires the submission of a result file which will be used to rank the users into groups of 10. The proposals that make the first group of ten will be invited to do demos on the workshop day, which will constitute the second round of evaluation. The results of this round will define the final ranking of the best performing proposals.
Important Dates
- The test set will be released to participants April 8, 2020
- The submission of results starts April 8, 2020
- The submission of results ends
May 1, 2020Extended to May 21, 2020 - The live demo at the MLC workshop June 11, 2020
In-Depth Description of The Task and Dataset
Version 1: M. Alrabeiah, J. Booth, A. Hredzak, and A. Alkhateeb,"ViWi Vision-Aided mmWave Beam Tracking: Dataset, Task, and Baseline Solutions" arXiv, Feb., 2020.
Citation and License
In order to use the ViWi datasets/codes, please cite
- The ViWi paper: M. Alrabeiah, A. Hredzak, Z. Liu, and A. Alkhateeb,"ViWi: A Deep Learning Dataset Framework for Vision-Aided Wireless Communications" submitted to IEEE Vehicular Technology Conference, Nov. 2019.
@InProceedings{Alrabeiah19,
author = {Alrabeiah, M. and Hredzak, A. and Liu, Z. and Alkhateeb, A.},
title = {ViWi: A Deep Learning Dataset Framework for Vision-Aided Wireless Communications},
booktitle = {submitted to IEEE Vehicular Technology Conference},
year = {2019},
month = {Nov.},
} - The Remcom Wireless InSite website: Remcom, Wireless insite,
https://www.remcom.com/wireless-insite
The ViWi dataset is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
 .
.
Questions and Feedback
- If you have any questions or feedback, please send to: ViWi.MLC AT gmail.com
Organizers
- Ahmed Alkhateeb, Arizona State University, US
- Muhammad Alrabeiah, Arizona State University, US
- Tim O'Shea, DeepSig & Virginia Tech, US
- Elisabeth de Carvalho, Aalborg University, DK
- Jakob Hoydis, Nokia Bell Labs, FR
- Marios Kountouris, EURECOM, FR
- Zhi Ding, UC Davis, US